Artificial Intelligence (AI) is a broad field that encompasses a range of approaches, techniques, and applications. Within AI, Machine Learning (ML) is a key area that focuses on developing algorithms and models that enable machines to learn from data and improve their performance over time.
Now, let's dive into the differences between Narrow or Weak AI, General or Strong AI, and Superintelligence:
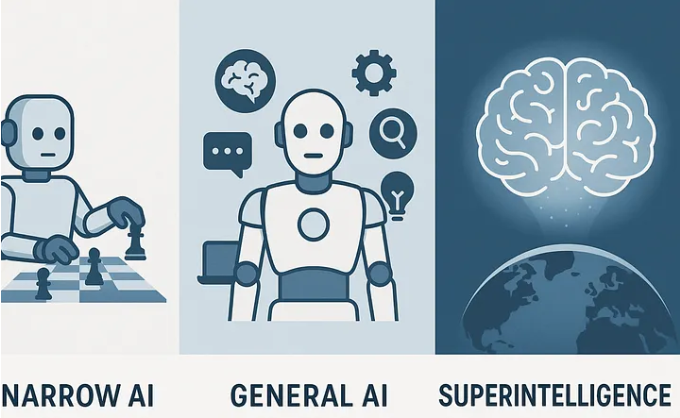
Narrow or Weak AI (Artificial Narrow Intelligence):
Focuses on a specific, well-defined problem or task, such as:
+ Image recognition
+ Natural Language Processing (NLP)
+ Speech recognition
+ Expert systems
Designed to perform a single task extremely well, often outperforming humans
Limited to a specific domain or task, not general reasoning or decision-making
Examples:
+ Google Assistant, Amazon Alexa, Siri (virtual assistants)
+ Image recognition systems
+ IBM Watson (limited to specific domains like medicine or finance)
General or Strong AI (Artificial General Intelligence):
Aims to create a human-like intelligence that can:
+ Reason abstractly
+ Learn from experience
+ Adapt to new situations
+ Apply knowledge across multiple domains
Should be able to perform any intellectual task that a human can
Still a long-term research goal, not yet achieved
Examples:
+ None (still in research and development)
Superintelligence (Artificial Superintelligence):
Significantly surpasses the cognitive abilities of humans in virtually all domains
Possesses an intelligence that is exponentially greater than the best human minds
Could potentially solve complex problems that are currently unsolvable
Could also pose significant risks to humanity if not aligned with human values and goals
Examples:
+ None (still purely theoretical and hypothetical)
To summarize:
Narrow or Weak AI is focused on specific tasks and excels in those areas.
General or Strong AI aims to replicate human-like intelligence, but it's still a long-term research goal.
Superintelligence is an exponential leap beyond human capabilities, with both immense benefits and potential risks.
While we've made tremendous progress in AI and ML, we're still far from achieving true human-like intelligence.
Now, let's dive into the differences between Narrow or Weak AI, General or Strong AI, and Superintelligence:
Narrow or Weak AI (Artificial Narrow Intelligence):
Focuses on a specific, well-defined problem or task, such as:
+ Image recognition
+ Natural Language Processing (NLP)
+ Speech recognition
+ Expert systems
Designed to perform a single task extremely well, often outperforming humans
Limited to a specific domain or task, not general reasoning or decision-making
Examples:
+ Google Assistant, Amazon Alexa, Siri (virtual assistants)
+ Image recognition systems
+ IBM Watson (limited to specific domains like medicine or finance)
General or Strong AI (Artificial General Intelligence):
Aims to create a human-like intelligence that can:
+ Reason abstractly
+ Learn from experience
+ Adapt to new situations
+ Apply knowledge across multiple domains
Should be able to perform any intellectual task that a human can
Still a long-term research goal, not yet achieved
Examples:
+ None (still in research and development)
Superintelligence (Artificial Superintelligence):
Significantly surpasses the cognitive abilities of humans in virtually all domains
Possesses an intelligence that is exponentially greater than the best human minds
Could potentially solve complex problems that are currently unsolvable
Could also pose significant risks to humanity if not aligned with human values and goals
Examples:
+ None (still purely theoretical and hypothetical)
To summarize:
Narrow or Weak AI is focused on specific tasks and excels in those areas.
General or Strong AI aims to replicate human-like intelligence, but it's still a long-term research goal.
Superintelligence is an exponential leap beyond human capabilities, with both immense benefits and potential risks.
While we've made tremendous progress in AI and ML, we're still far from achieving true human-like intelligence.
Class Sessions
1- Define artificial intelligence (AI) and its relationship to machine learning
2- Identify the roots and milestones in the history of artificial intelligence
3- Explain the differences between narrow or weak AI, general or strong AI, and superintelligence
4- Describe the types of problems that AI can solve, including classification, clustering, and decision-making
5- Recognize the applications of AI in various industries, such as healthcare, finance, and transportation
6- Discuss the benefits and limitations of AI, including job displacement and bias
7- Identify the key subfields of AI, including machine learning, natural language processing, and computer vision
8- Explain the concept of machine learning and its role in realizing AI capabilities
9-
10-
11- Identify the types of machine learning algorithms, including decision trees, support vector machines, and neural networks
12- Define what machine learning is and its importance in artificial intelligence
13- Identify the types of machine learning: supervised, unsupervised, and reinforcement learning
14- Analyze the importance of data quality and preprocessing in AI and machine learning
15- Explain the differences between supervised and unsupervised learning
16- Describe the concept of model training, validation, and testing in machine learning
17- Identify the key steps involved in the machine learning workflow: problem definition, data preparation, model training, model evaluation, and deployment
18- Explain the concept of overfitting and underfitting in machine learning models
19- Describe the importance of feature scaling and normalization in machine learning
20- Identify and explain the types of supervised learning: regression and classification
21- Explain the concept of cost functions or loss functions in machine learning
22- Describe the role of bias and variance in machine learning models
23- Define the importance of data preprocessing in machine learning and its impact on model performance
24- Describe the importance of data preprocessing in machine learning
25- Identify and describe different types of noise in datasets
26- Explain the concept of data cleaning and its techniques, including handling missing values and outliers
27- Apply feature scaling techniques, including logarithmic scaling and standardization
28- Explain the concept of feature selection and its importance in machine learning
29- Implement feature selection using correlation analysis and recursive feature elimination
30- Describe the concept of dimensionality reduction and its importance in machine learning
31- Identify and describe the importance of data transformation in machine learning
32- Apply data transformation techniques, including encoding categorical variables and handling non-linear relationships
33- Implement dimensionality reduction techniques, including PCA and t-SNE
34- Define supervised learning and its importance in machine learning
35- Explain the difference between regression and classification problems
36- Identify and describe the types of regression problems (simple and multiple)
37- Explain the concept of overfitting and underfitting in regression models
38- Describe the concept of classification and its types (binary and multi-class)
39- Explain the concept of bias-variance tradeoff in supervised learning
40- Design and implement a supervised learning model to solve a real-world problem
41- Compare and contrast different supervised learning algorithms (e.g. linear regression, logistic regression, decision trees)
42- Define unsupervised learning and its applications in real-world scenarios
43- Explain the concept of clustering and its types (hierarchical and non-hierarchical)
44- Identify the characteristics of a good clustering algorithm
45- Implement K-Means clustering algorithm using a programming language like Python
46- Evaluate the performance of a clustering model using metrics such as silhouette score and Calinski-Harabasz index
47- Explain the concept of dimensionality reduction and its importance in data analysis
48- Describe the difference between feature selection and feature extraction
49- Implement Principal Component Analysis (PCA) for dimensionality reduction
50- Apply t-Distributed Stochastic Neighbor Embedding (t-SNE) for non-linear dimensionality reduction
51- Define anomaly detection and its importance in machine learning
52- Identify the types of anomaly detection techniques (supervised, unsupervised, and semi-supervised)
53- Apply AI/ML concepts to a real-world problem to identify a tangible solution
54- Select a suitable problem domain and justify its relevance to AI/ML application
55- Formulate a clear problem statement and define key performance indicators (KPIs)
56- Conduct a literature review to identify existing solutions and approaches
57- Design and develop a custom AI/ML model to address the problem
58- Choose and justify the selection of a suitable AI/ML algorithm and techniques
59- Collect, preprocess, and visualize relevant data for model training and testing
60- Implement data augmentation techniques to enhance model performance
61- Reflect on the limitations and potential future developments of the project
62- Defend the project's methodology, results, and implications in a critical discussion
63- Project: Autonomous Thermal Inspection of 20 Wind Turbines